What's the future of machine learning going to look like? How can we attempt to predict what's going to come next given the rate of innovation? We can't make any predictions with certainty, but in this post I will examine past trends and ongoing work in an attempt to make predictions about the future.
The current paradigm of machine learning is "static" - users requests are shipped off to GPUs running in the cloud, inference is performed and results are returned. It seems unlikely that this paradigm will remain unchanged going forward. I believe the next paradigm of ML is "dynamic", with client side encoding of user specific information in model weights, models becoming more personalized, and your tertiary self adapting to you.
But this isn't some Jetsons fantasy, this future will arrive sooner than you think. Let's apply some first principles thinking in an attempt to understand when and how this will take shape.
The Past


Here's Bill Gates & Paul Allen sitting at a Teletype Model 33 ASR Terminal in 1968. This Model 33 would be connected to a General Electric computer designed for time-sharing, where requests from multiple users would be multiplexed in order to maximise compute utilization. Machine learning is much like this today, with a huge warehouse of A100s located in North Virginia undisclosed location that your device shares with 100,000s of others via API requests.
Much like the time-sharing of the 60's and 70's, this approach is destined to change as more compute is put into the hands of the users. Given todays computing capabilties, is it feasible to do machine learning on the client side?
First Principles Thinking
Let's do some back of the envelope calculations to evaluate if client side machine learning is currently feasible. There are 3 factors to consider:
- Memory - can we store the model parameters in (V)RAM on consumer hardware?
- Network - what size model can we reasonably ship to a user?
- Compute - can we perform inference (and possibly training) in a reasonable time?
Memory is not the bottleneck, since integrated GPUs share their memory with the CPU, and even mobile devices are commonly shipping with 4GB or more of RAM. 4GB equates to 2B FP16 parameters, or large enough to comfortably fit InstructGPT with enough to spare for an OS.
Network is more constrained, with the average internet speed in the United States currently sitting at ~150Mbit/s. This means that it would currently take ~140 seconds to download InstructGPT's 2.6GB FP16 weights. The download however, only needs to be done once, and can be cached client side.
Now onto compute, the focus of this essay. I'll be using an Apple M1 as our baseline (engineers bias). Disregarding the locked down Apple Neural Engine (ANE) for now, the M1 has an 8 core GPU with 128 execution units, capable of ~2.6 TFLOP/s of FP32 compute.
Unfortunately, the M1 GPU has 1:1 FP16/FP32 ratio [1], so we can't just double our FP32 FLOPs when we convert our models to FP16. But FP16 gives us a number of other advantages, like reducing memory usage and allowing easy offload to the ANE in future, so we will use this going forward.
We can say that a running a model client side is feasible when the following holds:
The median round trip time to all AWS servers from London is ~150ms (Check yours here). And yes, whilst this may be high for an E-corp with deployments in every AWS availability zone, or you who lives in undisclosed location, it's a good figure to start with. The A100 supposedly does 312 TFLOP/s of FP16 compute, or 120x faster than the M1 GPU. As the A100 is so fast, we will ignore the GPU inference time for now. Let's evaluate how much work we could do on the client side before the first packet even arrives at the data center.
From these figures, we can calculate that:
Keep this figure in mind as we explore where 390GFLOPs would be suitable given current model requirements.
Software 2.0
Karpathy talks alot about the Software 2.0 paradigm, where at Tesla, they replaced huge chunks of painstakingly written code with models who've learned the same functions. We can view applied machine learning from a functional programming perspective - a series of function applications, either defined by humans or learned by networks, to create incredibly complex behaviour. RunwayML talks about the success of model chaining for their AI powered video editor in this post.
Not all of the components in a model chain will have huge compute requirements. Stable Diffusion is an example of model chaining with varying compute needs, composed of 3 networks for different purposes. You can see the structure in the following diagram.
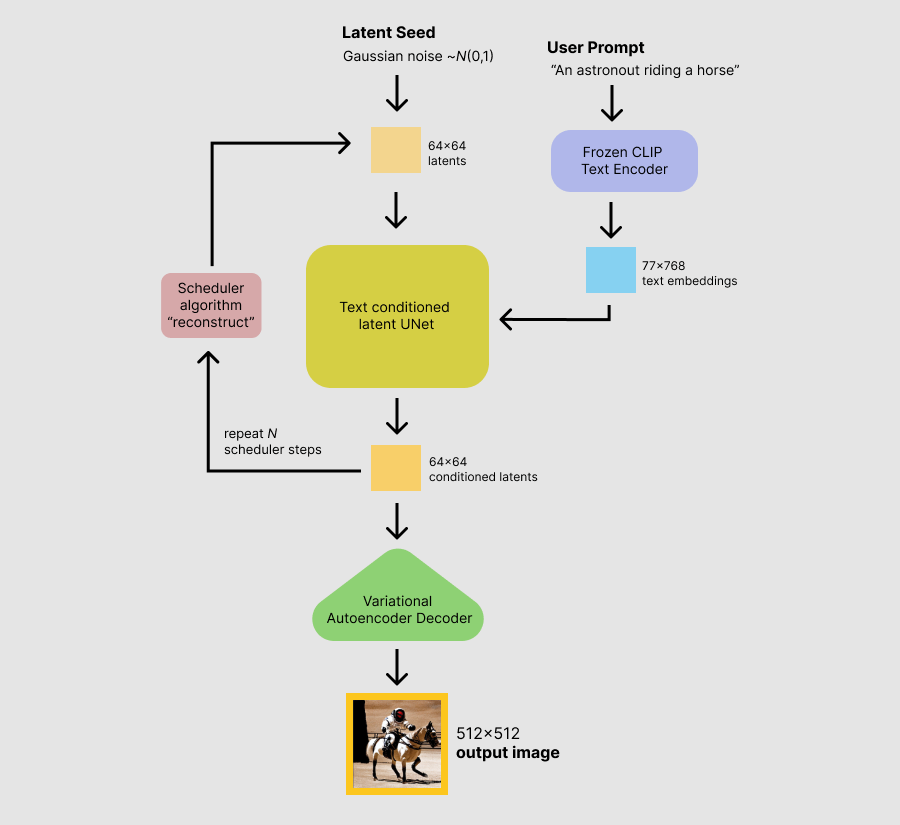
The main part of the network is the UNet, which consists of 860M parameters, or ~1.7GB of FP16 weights. This would have pretty huge memory, network & compute requirements, so let's focus on the lightest part of the network, the text encoder. Would it be possible to run the text encoder on the client side, and just ship the output vector to the cloud for inference?
To find out we need to profile it. Unlike my own toy profiler Steelix, which only supports a limited set of operations, Tract has no problem profiling the text encoder, telling us it takes around Fused Multiply Adds (FMA) or ~13.4GFLOPs for one forward pass (N.B We will use 1 FMA == 2 FLOPs [2], but this is the source of some debate).
Tract also tells us the text encoder uses parameters. This means that the FP16 parameters take up ~170MB of space. No problem for typical client side RAM, but still a sizeable file to ship over the network for a website. However, with techniques like compression, quantisation, distilation and pruning, we could certainly get the model size down to a managable download.
Given how many GFLOPs are required to do an inference pass, and how fast the M1 GPU is, we can calculate that the M1 can perform 29 inference passes in our 390GFLOPs budget. Before you protest, yes, since you have to go to the server anyway for the UNet and decoder, why not run the whole model there? This may result in the truly fastest experience, but from a pragmatic perspective, I am sure Stability would like to offload some % of their FLOPs onto the client with negligble impact on user experience.
Future Capabilities
To get a good look at how client side compute capabilities will grow, let's analyze the Apple A-series of mobile chips as an example (given their longer history than the M-series).
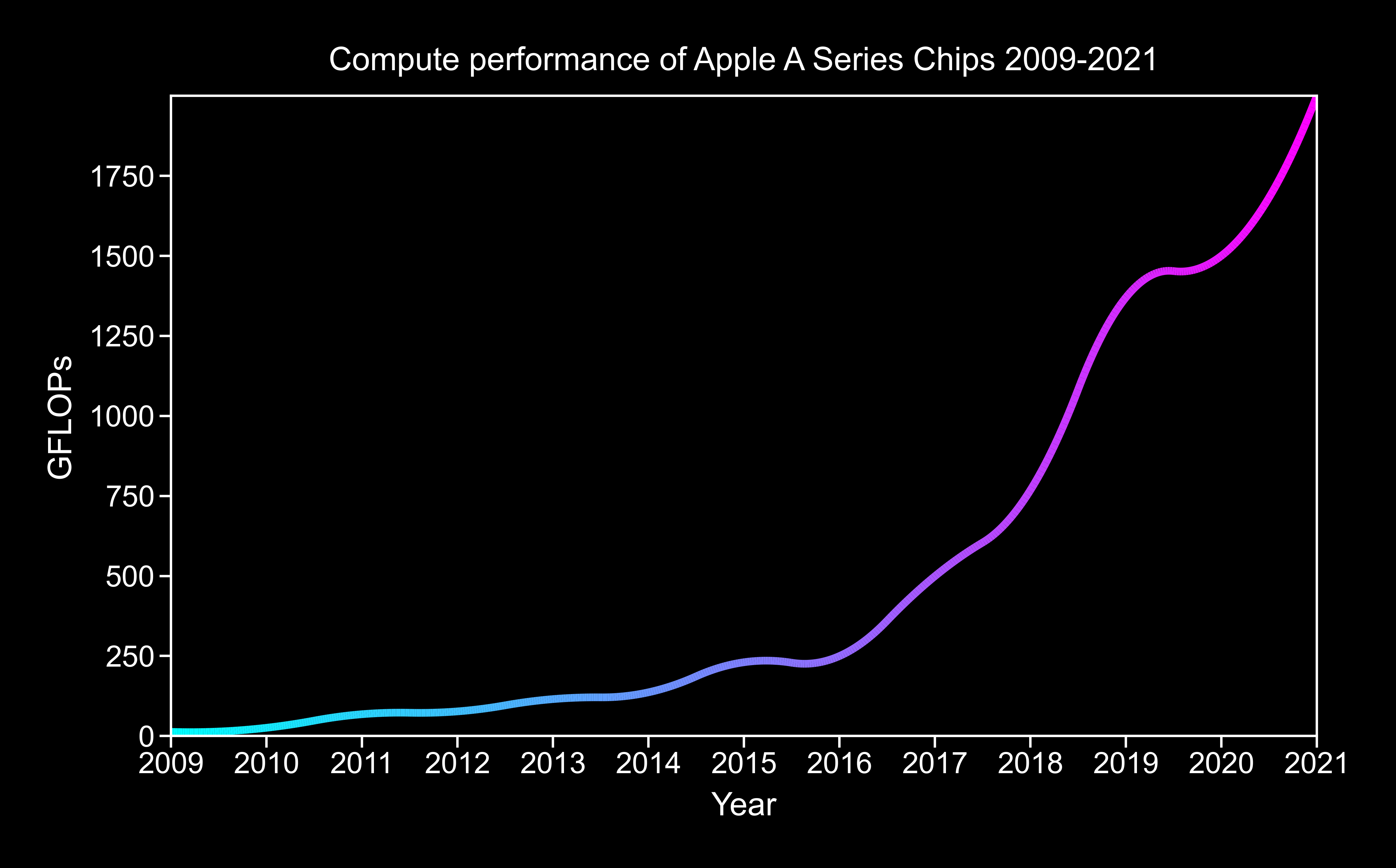
As we can see by the exponential growth, raw GPU compute is going to grow enormously on the client side (TSMC isn't out of ideas yet). This doesn't even begin to explore the custom silicon being shipped with ML in mind such as the aforementioned ANE.
Even if we just had the above exponential improvement in raw compute, we would certainly see client side machine learning capabilties grow. But that's not all. Improvements at the silicon level will only be complemented by improvements at the software level. Techniques such as Pruning, Distillation and RLHF all enable impressive capabilities in a small package. InstructGPT outputs were preferred by assessors whilst only having ~1/130 of the parameters of GPT-3!
The combination of these 2 factors means that we will have incredible ML capabilities within the next 24 months without a single packet ever needing to be sent to the cloud.
The next paradigm of machine learning
Now that we know that within the next few generations of hardware, machine learning capability on the client side will explode, what do these new capabilties enable?
Dynamic ML
When we have the capability of training networks client side, we will enter the era of dynamic machine learning. Models won't just be the same for everyone, and the weights will adapt dynamically as you use them.
A backwards pass (training) of a neural network takes approximately 2x the FLOPs of a foward pass (inference) [3]. So training larger models client side will arrive later than inference. But this isn't to say the idea is far fetched - the EfficientML lab has already proved it's possible to train networks on extremely resource constrained systems, such as a microcontroller with 256Kb of memory.
Lucky for us, we don't need to train an entire model client side, only fine tune a subset of the weights to get the dynamic behaviour we are looking for. This all sounds great, until some blob of weights on a server somewhere encodes every aspect of your life. It would be optimal if the subset of weights that get updated to learn about the user remained on their device.
It turns out using techniques like Adapters and LORA, you can simply pluck out different chunks of your Transformer, fine tune it on some new data, and plug it back in. Whilst those papers use it for finetuning a model for a new task, it should be feasible to fine tune a blob of weights locally using a user specific dataset. I expect it to be common place for users to be communicating with the data centre purely via seemingly meaningless vectors in the future.
How?
So, how can we deliver on the futuristic vision of the "The Intelligent Internet"?
It should be obvious that the web browser is the best software distribution platform ever created; enabling machine learning in the browser is going to be key. There have been rumblings in this direction for years, like TensorFlow.JS, ONNX Runtime Web and others, but none of them have ever made a huge impact.
Enter WebGPU. Taking up the torch from WebGL after a decade, WebGPU promises near native performance on the GPU. Unlike WebGL, WebGPU is designed with compute workloads in mind. This isn't some nuclear fusion style promise. WebGPU is coming, with the Chrome origin trial ending in January 2023.
W3 is taking it even further, with a dedicated Web Neural Network API arriving... eventually. But I'm not interested in waiting that long. To me, it looks possible to build yourself once you have access to the GPU - WONNX is a great attempt at this.
I think that building a consise ML framework designed from the ground up for WebGPU, capable of both inference and training, would enable a world of new possibilities. Rust seems well placed to do this, given that the whole WebGPU standard is implemented in Rust and powering FireFox already. Unfortunately, the first incarnation of WebGPU won't support INT8, so FP16 will have to do for now.
If you find this interesting - reach out to me.